Having complete and unfettered access to all parts of the world is important for NEO to accomplish tasks in home environments, and to enable our Redwood AI to learn from the broadest set of physical interactions possible. Our latest RL controller provides Redwood with a complete mobility toolkit to access the world, including natural walking in any direction, sitting, standing, kneeling, getting up from the floor, going up and down stairs with stereo vision. Bringing all of these capabilities together for the first time in a unified controller represents an important milestone in unlocking the full potential of humanoid robots.
Bridging Natural Movement with Omnidirectional steering
The past decade has seen rapid progress in legged robot locomotion, primarily driven by torque-transparent actuators, deep Reinforcement Learning (RL) algorithms, and GPU-accelerated simulation. Using off-the-shelf software packages and a desktop GPU, it is now possible to train a bipedal robot to stand upright in simulation and follow walking direction commands in under an hour. Even though the policy is trained completely in a simulation environment whose physics are merely an approximation of the real world, it is trained on so many randomized physics parameters – e.g. friction, mass, sensor noise – that the model ends up being robust to the real world’s physics parameters. Once trained, this walking controller can receive walking direction commands from either the teleoperator or the AI model (e.g. Redwood), and then translate those high level directions into the dynamic, contact-aware interactions with the world.
Beyond walking and turning, bipeds can also perform side-stepping. This is useful for navigating the close quarters of a kitchen or the space between the sofa and the coffee table, where the footprint would be too small for a wheeled base robot.
However, these basic walking RL controllers often require additional “shaping rewards” to achieve a natural human-like gait in all directions. These tend to be highly specialized to walking, which means that the same process of hand-tuning rewards must be repeated for every new behavior. Gait patterns can vary based on the direction of walking, so this often requires unique shaping terms based on the direction of motion.
Is there a more scalable way to increase controller capabilities without hand-written shaping rewards for each of them? One method is to collect motion capture references from humans moving naturally, retarget them to NEO’s joints and body, and then train the RL controller to match those kinematic reference trajectories.
Because the reference only specifies where the body should be, the RL controller still needs to figure out how to keep the robot stable, while “keeping tempo” and tracking the reference trajectory as closely as possible.
Using these techniques, it is possible to over-fit a policy to track a single human motion capture trajectory and achieve very dynamic and fluid motions such as dancing or walking. Examples of “single trajectory replay controller” are shown below for natural running and pivoting:
These behaviors, while elegant, are not readily useful for general purpose tasks as they only can replay a single trajectory. They do not expose a steerable interface with which a high level policy like the AI model can execute the right actions. It is also not obvious how to transition smoothly from one reference to another, as motion capture datasets rarely include the transition behaviors between arbitrary task-centric motions, e.g. switching from shuffling quickly side-to-side to a skipping motion.
To handle multiple trajectories, we could train the controller to follow multiple mocap references, taking in the encoded kinematic trajectory as an input. However, this approach encounters a teleoperation UX problem: it is not obvious how one provides the high-dimensional kinematic trajectories at test-time using a more limited input device like a gamepad joystick or a VR controller. The model is trained on high-dimensional kinematic trajectories with nuanced rhythm and periodicity, but the commands provided by teleoperation are coarse-grained, which results in the RL controller interpreting it into an unnatural gait.
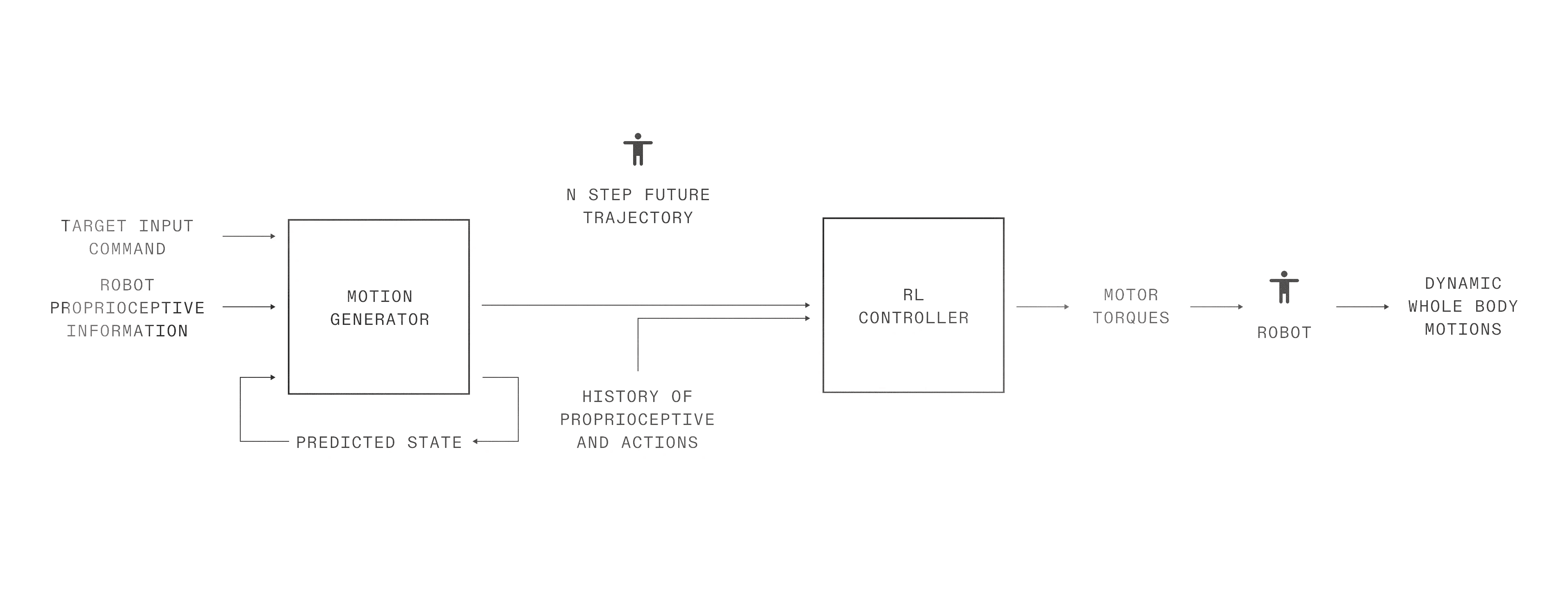
How does one achieve steerability and robustness, while still achieving the fluidity of motion capture-based RL training? We developed a two-stage controller, consisting of a high level “kinematic planner” to synthesize kinematic targets that resemble human motion capture data, and a low level controller that tries to achieve those plans.
The lower level RL controller takes as input a kinematic reference trajectory of body poses that it must attempt to track while maintaining balance. This is paired with a high level motion generator model that is trained with supervised learning to convert input commands like joystick direction to the richer kinematic trajectories. The generative model also plays the role of smoothing transitions during behavior changes.
Stairs
An important reason for having robots with legs in the home is to traverse stairs. We develop a “stair mode” in our controller which engages the use of stereo RGB vision to infer the height of the floor around NEO.
To climb up and down stairs in a graceful way, NEO’s RL controller must anticipate the necessary height of each step well in advance of making contact with that step. Unlike most humanoid robots, which employ a time-of-flight depth sensor or a lidar to estimate the floor plane, NEO’s RL controller is purely vision based. Depth is predicted directly from the RGB stereo pair, and this is fused with the proprioceptive history for NEO to figure out how and where to step.
Stairs are not always idealized; through domain randomization in simulation, the controller is also robust enough to support side-stepping and handling stairs of mixed heights.
Getting Down and Getting Up
There are numerous home chores that require NEO to work at floor height for extended periods of time: removing a stain from the carpet, reorganizing the bottom drawer of a cabinet, packing a suitcase, and sorting socks. We extend our RL controller to be able to safely sit, kneel and lie down on the floor, as well as get back up from each of these poses.
Redwood x RL
The controller provides an “action interface” for which teleoperation or Redwood AI is able to interact in a safe, contact-rich manner with the physical world. To demonstrate the controllability of the natural walking behavior, we fine-tuned the Redwood model to do a soccer ball dribbling task.
Here is Redwood interacting with this new RL controller, where it predicts whole body joint targets and walking pelvis velocities from vision. The controller then translates those intents into the specific forces applied by the leg to walk in the direction of the ball.
Conclusion
We have developed the first general-purpose, fully AI and teleoperation compatible controller that unlocks the full kinematic workspace that is available to a bipedal humanoid robot. This will enable us to train Redwood AI to fully explore the entire state space of the home: every high and low shelf, every nook and cranny, every floor.
We will then use that data to make an AI like no one has ever seen.